Active Learning
We all know that algorithms are better at board games than humans beating the world’s best, first at chess and more recently Go. We wanted to explore whether similar results would play out in areas of drug discovery.
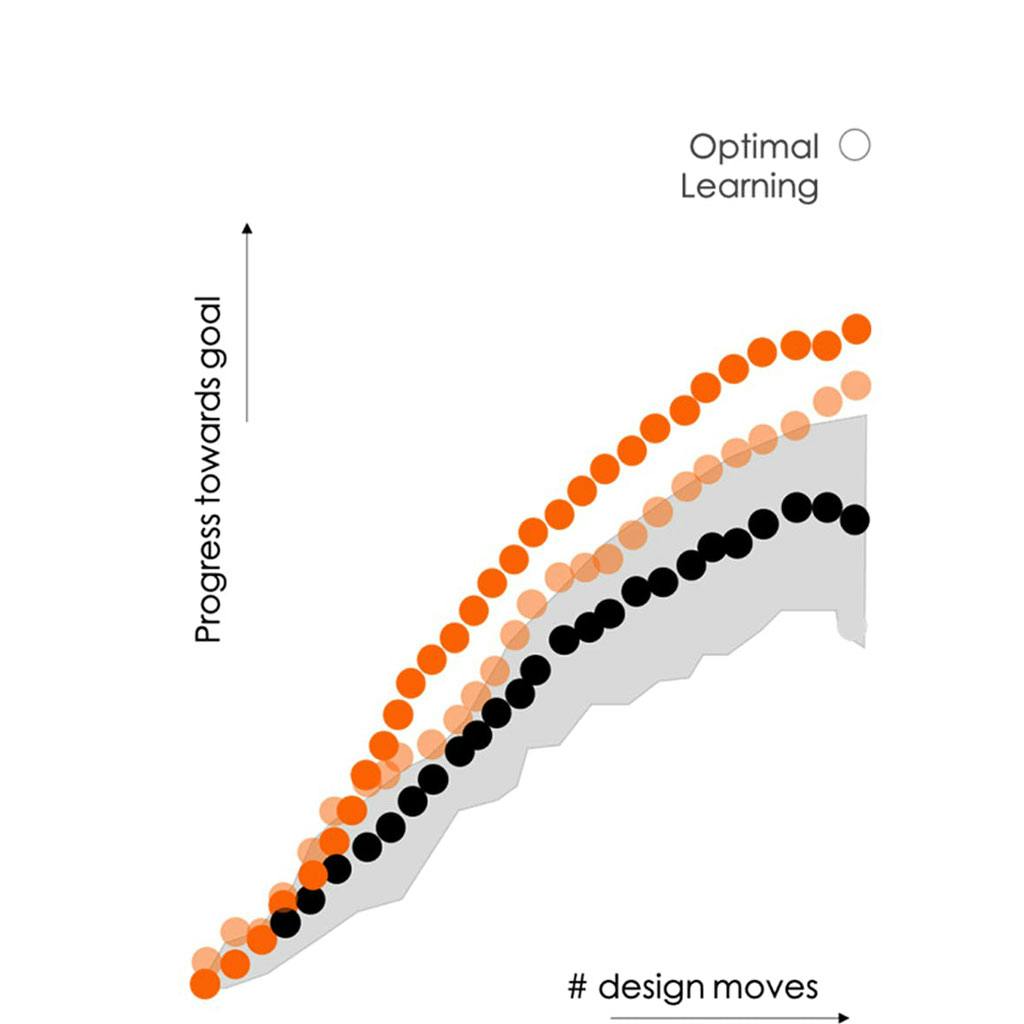
We all know that algorithms are better at board games than humans beating the world’s best, first at chess and more recently Go. We wanted to explore whether similar results would play out in areas of drug discovery.